Managing Millions of Messages with RabbitMQ: Our Experience and Strategies


Our task was to collect data from nine countries and standardize it into a specific format, after which we had to provide it to other teams for further processing. This required us to handle thousands of messages daily and perform database operations on them. On certain occasions, we were provided with complete data dumps, which increased the publishing rate to around 4000 to 5000 messages per second.
Real Case Scenario
We faced was that a high rate of message publishing that caused the RabbitMQ queues to exceed their length limits. Our initial solution was to scale up by adding more consumers, but even with over 20 consumers, the system struggled to handle the large volume of messages. While batch processing of DB operations and creating the right indexes helped somewhat, it did not prevent the queue from eventually getting full.
Also, It's not feasible to handle data import/export offline, as this would lead to data inconsistency since the data is updated daily.
In the end, the code was designed to handle concurrent processes by using an asynchronous approach.
Adding Redis Layer
In an effort to resolve the problem, we explored various solutions and decided to introduce a Redis layer between RabbitMQ and the downstream workers. By introducing Redis as a buffer with a large queue capacity, the messages would be transferred from RabbitMQ to Redis, and then consumed directly by Redis workers. This approach helped to mitigate the issue of RabbitMQ queues overflowing and allowed for a more stable message processing system. By adopting this approach, we were able to optimize our messaging system's performance and improve the overall efficiency of our data processing pipeline.
This solution allowed us to utilize RabbitMQ as a reliable means of receiving messages, while the actual message consumption and processing took place through Redis. With Redis acting as an intermediary buffer, we were able to handle large volumes of messages without overburdening the RabbitMQ queues.
This approach also allowed us to process messages in batches, which helped to improve the overall efficiency of our database operations. By processing messages in batches, we minimised the number of individual database operations required, which in turn helped to reduce the processing time and increase overall system performance.
Overall, this approach proved to be an effective solution for managing high volumes of messages and helped us to achieve our goals of optimizing message processing and improving system performance.
Technical Implementation
Our team relied on the powerful combination of Helm and Kubernetes to deploy our services within the GCP environment. Our deployment approach primarily focused on deploying consumer instances, which were specifically built to handle message processing and database operations.
As for RabbitMQ, it was deployed at the root level by the infrastructure team. This meant that each team within the company used the same RabbitMQ per environment. This approach allowed for greater efficiency and consistency across different teams and services.
We opted to use Mongo Atlas as our database solution due to its ability to provide a scalable cluster solution. This meant that we could easily scale up or down depending on the volume of data being processed, ensuring that our services were able to handle large volumes of messages without any performance issues.
With the power and flexibility of Mongo Atlas, we were able to build and deploy robust services that were able to handle the complex demands of our message-processing workflows effectively.
Previously, we deployed Redis standalone with Helm and K8S. However, we frequently encountered issues where Redis would crash due to overflow or faulty code logic. This not only caused issues with Redis itself but also impacted the performance of KEDA, which was not ideal for large-scale applications.
As a result, we have moved away from deploying Redis independently and instead started using MemoryStore in GCP. MemoryStore has been performing as expected and has helped us avoid the issues we were experiencing with Redis. Overall, we have found that MemoryStore is a more reliable solution for large-scale applications.
Overall, the simple high overview of architecture will be like below:
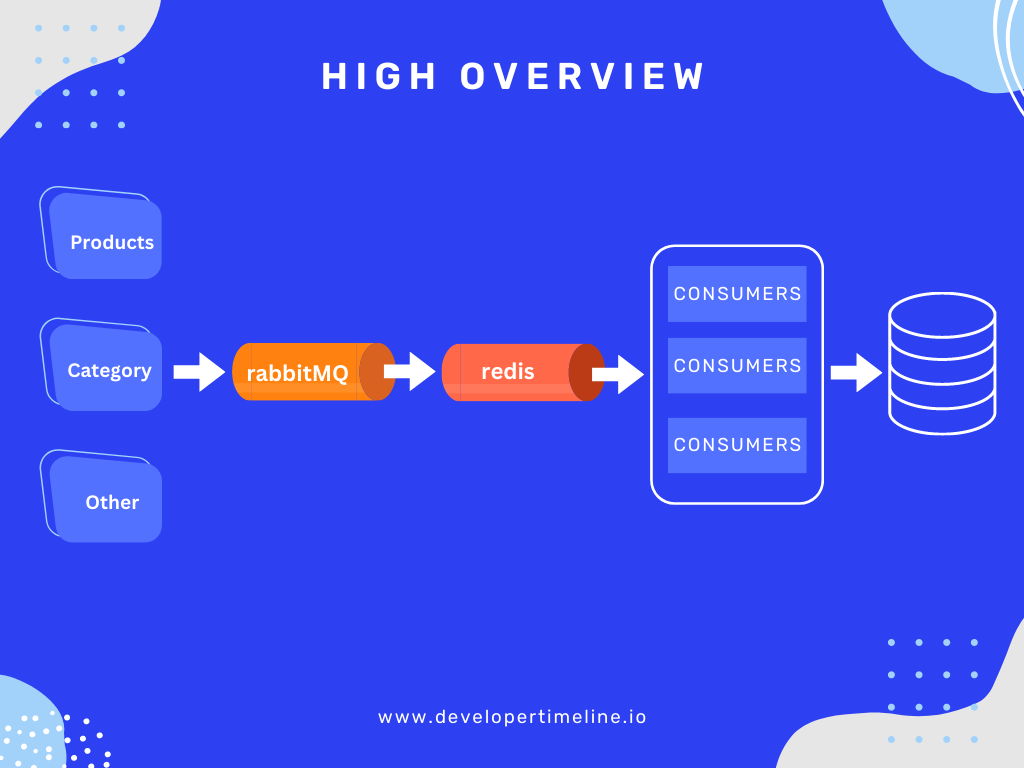
As mentioned earlier, the messages will originate from multiple sources and initially be sent to RabbitMQ. However, due to the high volume of messages being published per second, the queue can easily become overwhelmed.
As a result, instead of consuming the messages directly, they are forwarded to Redis. The messages are then processed in batches from Redis and saved into Mongo.
Conclusion
In conclusion, our team successfully completed the task of collecting and standardizing data from nine different countries, and effectively provided it to other teams for further processing. This task required us to handle a large volume of messages on a daily basis and perform complex database operations, including managing complete data dumps that significantly increased the publishing rate. Despite these challenges, our team's dedication and hard work enabled us to achieve our objectives and deliver quality results to our clients.